Loaders¶
The Loader stage can be used to create visualizations, plots, and other files based on the data frame from the Transformer stage.
Save as Csv¶
- pydantic model doespy.etl.steps.loaders.CsvSummaryLoader[source]¶
The CsvSummaryLoader creates a CSV file of the data frame from the Transformer stage.
Example ETL Pipeline Design¶$ETL$: loaders: CsvSummaryLoader: {} # with default output dir CsvSummaryLoader: # with skip empty df skip_empty: True
- field skip_empty: bool = False¶
Ignore empty df, if set to
False, raises an error if the data frame is empty.
Save as Pickle¶
- pydantic model doespy.etl.steps.loaders.PickleSummaryLoader[source]¶
The PickleSummaryLoader creates a Pickle file of the data frame from the Transformer stage.
Example ETL Pipeline Design¶$ETL$: loaders: PickleSummaryLoader: {} # with default output dir PickleSummaryLoader: # with skip empty dir skip_empty: True
- field skip_empty: bool = False¶
Ignore empty df, if set to
False, raises an error if the data frame is empty.
Save as Latex Table¶
- pydantic model doespy.etl.steps.loaders.LatexTableLoader[source]¶
The LatexTableLoader creates a tex file of the data frame from the Transformer stage formatted as a Latex table.
Example ETL Pipeline Design¶$ETL$: loaders: LatexTableLoader: {} # with default output dir LatexTableLoader: # with skip empty df skip_empty: True
- field skip_empty: bool = False¶
Ignore empty df, if set to
False, raises an error if the data frame is empty.
Advanced Plots: Column Cross¶
The most flexible Loader is a project-specific loader tailored precisely to its requirements.
However, many projects share similar needs when it comes to visualizing data frames.
To streamline this process and help with best-practices, we introduce an extensible, universal solution: the ColumnCrossPlotLoader.
This versatile Loader empowers users to create a diverse array of plots, including various forms of bar charts.
By configuring parameters within the ETL step, users can customize the ColumnCrossPlotLoader to suit their specific needs.
See demo_project/doe-suite-config/super_etl/demo02-colcross.yml for an example of how to configure the ColumnCrossPlotLoader.
Moreover, the ColumnCrossPlotLoader offers multiple hooking points, enabling further customization through the integration of custom code.
This ensures that users have the flexibility to leverage the basic features even if they have a highly specialized requirement.
See demo_project/doe-suite-config/does_etl_custom/etl/plots/colcross.py for an example of how to extend the loader with custom components.
- pydantic model doespy.etl.steps.colcross.colcross.ColumnCrossPlotLoader[source]¶
The ColumnCrossPlotLoader facilitates the creation of multiple figures, each potentially containing a subplot grid (e.g., a 2-by-3 grid) derived from the DataFrame’s data.
The use of cumulative configurations (e.g., cum_plot_config, cum_subplot_config, cum_artist_config) enables to individually control the appearance of each figure, subplot, and artist (e.g., bar, line) appearing in a subplot.
The ColumnCrossPlotLoader is intentionally designed to be extensible and adaptable, facilitating the integration of custom code. This can be achieved by creating a new project-specific Loader that inherits the base functionality.
- field data_filter: DataFilter [Optional]¶
Filter the DataFrame to include only the specified values from a predefined list and establish a sorting order.
Example¶data_filter: allowed: col1: [val1, val2] # filter out rows where col1 is not val1 or val2 + sort col1 (in that order) col2: [val3, val4, val5] # filter out rows where col2 is not val3, val4, or val5 + sort col2 # col3 is not present, so all values are allowed
- field fig_foreach: ColsForEach [Optional]¶
Generate an indiviudal figure (file) for each unique combination of values found within the given columns.
Example¶fig_foreach: cols: [col1, col2] # create a figure for each unique combination of values in col1 and col2 jp_except: "(col1 == 'A') && (col2 == 'B')" # optional: exclude specific combinations
- field metrics: Dict[str, Metric] [Required]¶
A dictionary containing metrics that describe the format of measurement data (i.e., what you typically would visualize on the y-axis of a plot).
Each entry comprises a key-value pair, with the key representing the metric name and the value denoting its configuration. The metric configuration specifies the columns in the dataframe where the data is stored, along with details such as units. Additionally, it enables conversion to other units as needed.
Each subplot will be built based on exactly one metric. Use the special key
$metrics$in e.g.,plot_foreachandsubplot_gridto create a plot / subplot for every metric.Example¶metrics: time: value_cols: [col1_ms] # col1_ms contains the data value_divider: 1000 # convert from ms to sec unit_label: "sec" # could have further metrics
- field cum_plot_config: List[PlotConfig] = []¶
“This list contains plot configurations that are merged to create one plot configuration for each figure (refer to ‘fig_foreach’).
The configurations are merged cumulatively, giving priority to those listed earlier in case of conflicts.
By utilizing the
jp_queryin list entries, you can create figure-specific configurations based on the data used to generate them (i.e., the columns specified in ‘fig_foreach’).Example¶cum_plot_config: - jp_query: "(col1 == 'A')" legend_fig: {label: {template: "{col2}"}} # show a legend in figure where col1 == 'A' - # could have further configs
- field cum_subplot_config: List[SubplotConfig] [Required]¶
This list contains subplot configurations that are merged to create one configuration for each subplot in all figures (refer to
fig_foreach, andsubplot_grid).The configurations are merged cumulatively, giving priority to those listed earlier in case of conflicts.
By utilizing the
jp_queryin list entries, you can create subplot-specific configurations based on the data used to generate them (i.e., the columns specified in ‘fig_foreach’, andsubplot_grid). For example, this allows you to use different chart types (bar, line, etc.) or a different color scheme for different subplots.Example¶cum_subplot_config: - jp_query: "(col1 == 'A')" # only for subplots where col1 == 'A' legend_ax: {label: {template: "{col2}"}} ... - chart: ... # in all subplots have the same chart type ... # check SubplotConfig for more options
Configurations (Cumulative)¶
The ColumnCrossPlotLoader facilitates the creation of multiple figures, potentially containing grids of subplots, each presenting a chart composed of multiple artists.
To ensure maximum customization flexibility, the loader allows to configure every aspect separately. This is achieved through cumulative lists, that are merged to establish configurations for figure-level attributes, subplot-level attributes, and individual artists.
The configurations are merged cumulatively, giving priority to those listed earlier in case of conflicts.
Leveraging the jp_query within list entries enables the creation of specific configurations tailored to the data used for their generation.
Each figure, subplot, and artist (e.g., a bar segment in a stacked bar chart) is assigned a unique identifier based on the underlying data. These identifiers can be used to address particular configurations to subsets of plots, subplots, and artists.
For instance, subplots may have different chart types, or specific bars may require distinct colors.
Hence, by formulating a jp_query that matches on the identifer of a specific bar, we can apply a unique color to that bar.
Conceptually, the generation process is a hierarchical series of groupby operations.
At each level, an ID is assigned – a flat JSON/dictionary object comprising key-value pairs derived from the grouping columns of the current level and all preceding levels.
For instance, if figures are created for each unique value in the ‘year’ column, resulting identifiers follow the format plot_id = {'year': 2000} or plot_id = {'year': 2001}.
In addition to the grouping columns, IDs include supplementary information, such as the row and column indices of a subplot within a grid.
Below we show the hierarchical structure of the IDs, starting from the top-level figure and descending to the lowest-level artist:
GroupBy Figure Cols
├── Figure1
| GroupBy Subplot Cols
│ ├── Subplot1
│ │ GroupBy Group Cols
│ │ ├── Group1
| | | GroupBy Element Cols
| │ │ ├── Element1
| │ │ │ GroupBy Part Cols
| │ │ │ ├── Artist1
| │ │ │ └── Artist2
| │ ...
| |
│ ├── Subplot2
│ │ GroupBy Group Cols
| ...
|
├── Figure2
| GroupBy Subplot Cols
│ └── ...
|
| ...
An example featuring a single figure comprising two subplots positioned side by side. One subplot showcases a grouped stacked bar chart, while the other contains a simple bar chart.
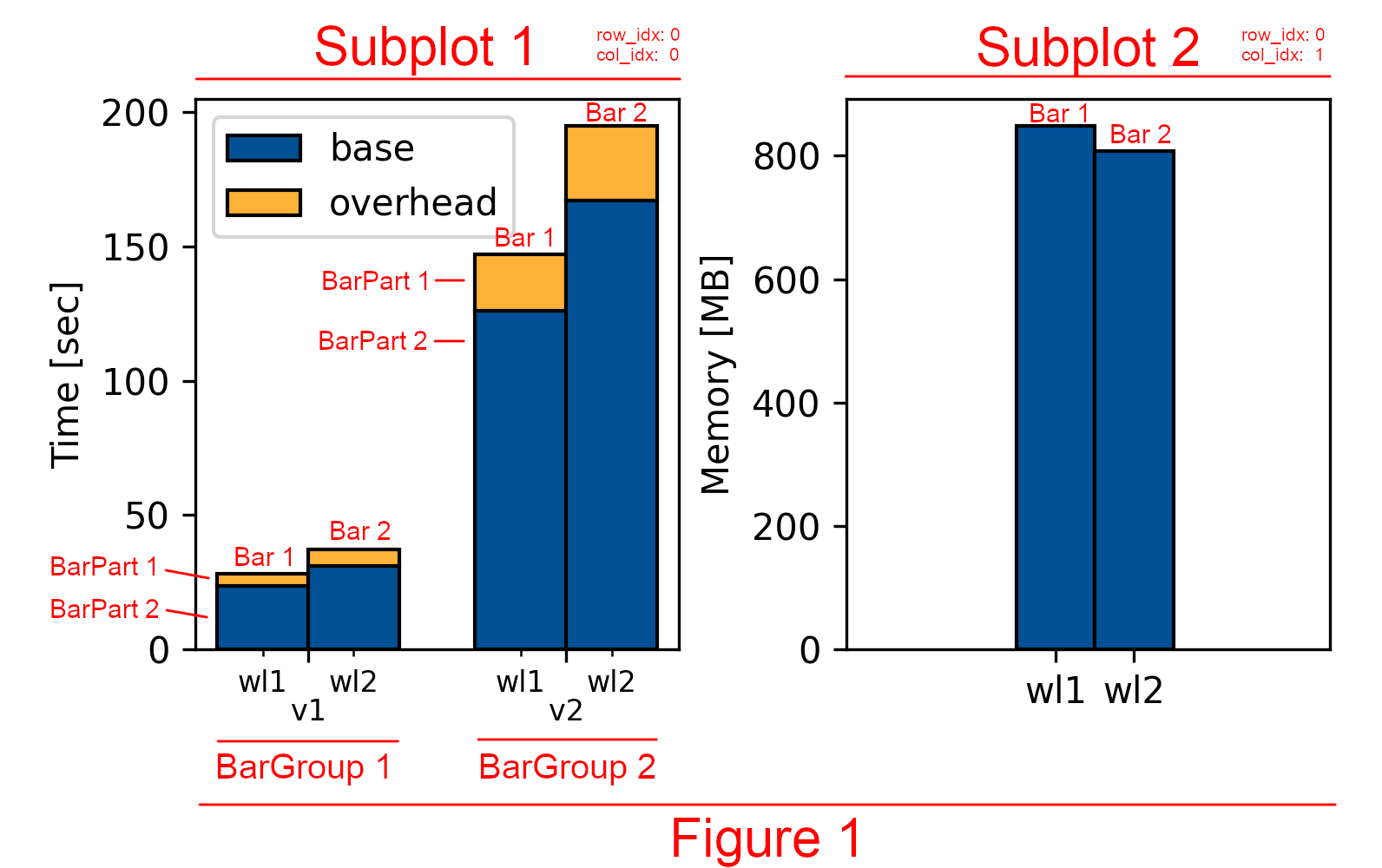
GroupBy Figure Cols
└── Figure1 # only one figure
GroupBy Metric [Time, Memory] # subplot cols
├── Subplot1 -> Time # [row_idx=0, col_idx=0] # grouped stacked bar chart
│ GroupBy System Config [v1, v2] # group cols
│ ├── BarGroup1 -> v1
| | GroupBy Workload [wl1, wl2] # bar cols
│ | |
│ │ ├── Bar1 -> wl1
│ │ │ GroupBy part [overhead, base] # part cols
│ │ │ ├── BarPart1 -> overhead # Artist1
│ │ │ └── BarPart2 -> base # Artist2
| | |
│ │ └── Bar2 -> wl2
│ │ GroupBy part [overhead, base] # part cols
│ │ ├── BarPart1 -> overhead # Artist1
│ │ └── BarPart2 -> base # Artist2
| |
│ └── BarGroup2 -> v2
| GroupBy Workload [wl1, wl2] # bar cols
│ |
│ ├── Bar1 -> wl1
│ │ GroupBy part [overhead, base] # part cols
│ │ ├── BarPart1 -> overhead # Artist1
│ │ └── BarPart2 -> base # Artist2
| |
│ └── Bar2 -> wl2
│ GroupBy part [overhead, base] # part cols
│ ├── BarPart1 -> overhead # Artist1
│ └── BarPart2 -> base # Artist2
|
|
└── Subplot2 -> Memory # [row_idx=0, col_idx=1] # simple bar chart (no groups, no stacks)
GroupBy Workload [wl1, wl2] # bar cols
├── Bar1 -> wl1 # Artist1
└── Bar2 -> wl2 # Artist2
# fig_foreach:
# cols: [col1, col2]
plot_id = {'col1': '<value>', 'col2': '<value>'}
Where col1 and col2 are the columns used to group the data frame, and <value> is the unique value of the group.
# fig_foreach:
# cols: [col1, col2]
# subplot_grid:
# rows: [col3, $metrics$]
# cols: [col4]
# metrics:
# time: ...
# memory: ...
subplot_id = {
# figure level
'col1': '<value>', 'col2': '<value>',
# subplot level
'col3': '<value>', 'col4': '<value>',
'subplot_row_idx': '<idx>', 'subplot_col_idx': '<idx>', # grid position
'$metrics$': '<metric.name>', '$metric_unit$': '<metric.unit_label>' # metric info
}
Where col1, col2, col3, col4 are the columns in the data frame, and <value> is a corresponding value.
The subplot_row_idx and subplot_col_idx are the row and column indices of the subplot within the grid.
Each subplot always has a single metric, which describe the data columns used to generate the chart.
The special keyword $metrics$ can be used in plot_foreach```or ``subplot_grid to specify how multiple metrics are handled.
The respective id, contains the key $metrics$ with the metric name, and $metric_unit$ with the metric unit label.
Which ids are available below the subplot level depends on the chart type. However, a typical id could be for a group (e.g., group of bars).
# fig_foreach:
# cols: [col1, col2]
# subplot_grid:
# rows: [col3, $metrics$]
# cols: [col4]
# metrics:
# time: ...
# as part of the chart:
# group_foreach:
# cols: [col5, col6]
group_id = {
# figure level
'col1': '<value>', 'col2': '<value>',
# subplot level
'col3': '<value>', 'col4': '<value>',
'subplot_row_idx': '<idx>', 'subplot_col_idx': '<idx>', # grid position
'$metrics$': '<metric.name>', '$metric_unit$': '<metric.unit_label>' # metric info
# group level
'col5': '<value>', 'col6': '<value>',
}
Plot Config¶
- pydantic model doespy.etl.steps.colcross.colcross.PlotConfig[source]¶
The PlotConfig class is used to configure the appearance of figure-level aspects.
- field legend_fig: Optional[LegendConfig] = None¶
Configuring a figure-wide legend (refer to
legend_axfor subplot-specific legends).
- field subplot_grid: Optional[SubplotGrid] = None¶
Create a grid of subplots within a single figure, where each subplot corresponds to a unique combination of values from specified row and column columns.
Example¶# grid has a row for every unique value in col1 and # a column for every unique combination of values in col2 and col3 # (except for the excluded combination) subplot_grid: rows: [col1] cols: [col2, col3] jp_except: "(col1 == 'A') && (col2 == 'B')" # optional: exclude specific combinations
- field jp_query: str = None¶
The JMESPath query is applied to the plot_id (i.e., dict of col:data pairs) to determine whether this configuration entry applies or not. If the jp_query matches, then this configuration applies. If None, then this config applies to all plot_ids.
Subplot Config¶
- pydantic model doespy.etl.steps.colcross.colcross.SubplotConfig[source]¶
The SubplotConfig class is used to configure the appearance of a subplot within a figure.
- field chart: Union[GroupedStackedBarChart, GroupedBoxplotChart] = None¶
The type of chart used within the subplot.
- field label_map: Dict[str, str] = None¶
A dictionary mapping original data values to labels formatted for the plot.
Whenever a label is displayed, the original data value is replaced with the corresponding label (if a matching entry exists).
- field ax_title: LabelFormatter = None¶
Assign a title to the subplot.
- field legend_ax: LegendConfig = None¶
Assign a subplot-specific legend.
- field xaxis: AxisConfig = None¶
Configure the x-axis of the subplot.
- field yaxis: AxisConfig = None¶
Configure the y-axis of the subplot.
- field cum_artist_config: List[ArtistConfig] = None¶
“This list contains artist configurations that are merged to create one artist configuration for each artist (e.g., a bar part, a line, etc.).
The configurations are merged cumulatively, giving priority to those listed earlier in case of conflicts.
By utilizing the
jp_queryin list entries, you can create artist-specific configurations based on the data used to generate them. For example, the color of one of the bars should be different in a specific subplot.
- field jp_query: str = None¶
The JMESPath query is applied to the subplot_id (i.e., dict of col:data pairs) to determine whether this configuration entry applies or not. If the jp_query matches, then this configuration applies. If None, then this config applies to all subplot_ids.
Artist Config¶
- pydantic model doespy.etl.steps.colcross.components.ArtistConfig[source]¶
Configure settings for a specific artist (e.g., line, bar, scatter, etc.).
This configuration allows customization beyond the predefined fields listed below. Additional options can be passed as keyword arguments (kwargs) to the matplotlib function corresponding to the artist.
For instance, setting {color: blue} for a bar plot would define the bars’ color as blue.
Refer to the specific artist or chart type documentation for a comprehensive list of available customization options.
- field jp_query: Optional[str] = None¶
The JMESPath query is applied to the artist_id (i.e., dict of col:data pairs) to determine whether this configuration entry applies or not. If the jp_query matches, then this configuration applies. If None, then this config applies to all artist_ids.
- field label: Union[LabelFormatter, str] = None¶
Special label formatter that allows to customize the label used for the artist.
Supported Chart Types¶
Grouped Stacked Bar Chart¶
- pydantic model doespy.etl.steps.colcross.subplots.bar.GroupedStackedBarChart[source]¶
- field group_foreach: ColsForEach [Optional]¶
Generate an indiviudal group (of bars) for each unique combination of values found within the given columns.
If missing, then only a single group is formed (i.e., no groups).
Example¶group_foreach: cols: [col1, col2] # create a group for each unique combination of values in col1 and col2 jp_except: "(col1 == 'A') && (col2 == 'B')" # optional: exclude specific combinations
- field bar_foreach: ColsForEach [Required]¶
Within a group (of bars), generate a bar for each unique combination of values found within the given columns.
Example¶bar_foreach: cols: [col3, col4] # create a bar for each unique combination of values in col3 and col4 # optional: exclude specific combinations (can also use cols from group_foreach, fig_foreach, etc.) jp_except: "(col1 == 'A') && (col3 == 'B')"
- field part_foreach: ColsForEach [Optional]¶
To create a stacked bar, each bar consists of multiple parts.
Within a bar generate a bar part for each unique combination of values found within the given columns. In addition, the columns of the
Metric(i.e., $metrics$) will also result in multiple parts.If missing, only the
Metriccolumns will be used. If theMetriconly has a single column andpart_foreachis missing, then a regular (i.e. non-stacked) bar chart is created.Example¶# the columns under metrics also result in parts part_foreach: cols: [col5, col6] # create a bar part for each unique combination of values in col5 and col6 # optional: exclude specific combinations (can also use cols from group_foreach, bar_foreach, etc.) jp_except: "(col1 == 'A') && (col5 == 'B')"
- field bar_width: float = 0.6¶
The width of each bar.
- field bar_padding: float = 0.0¶
The space between bars within a group.
- field group_padding: float = 0.1¶
The space between groups.
Grouped Boxplot¶
- pydantic model doespy.etl.steps.colcross.subplots.box.GroupedBoxplotChart[source]¶
- field group_foreach: ColsForEach [Optional]¶
Generate an indiviudal group (of boxes) for each unique combination of values found within the given columns.
If missing, then only a single group is formed (i.e., no groups).
Example¶group_foreach: cols: [col1, col2] # create a group for each unique combination of values in col1 and col2 jp_except: "(col1 == 'A') && (col2 == 'B')" # optional: exclude specific combinations
- field box_foreach: ColsForEach [Required]¶
Within a group (of boxes), generate a box for each unique combination of values found within the given columns.
Example¶box_foreach: cols: [col3, col4] # create a box for each unique combination of values in col3 and col4 # optional: exclude specific combinations (can also use cols from group_foreach, fig_foreach, etc.) jp_except: "(col1 == 'A') && (col3 == 'B')"
- field part_foreach: ColsForEach [Optional]¶
Create multiple boxes in the same x-axis position for each unique combination of values found within the given columns. In addition, the columns of the
Metric(i.e., $metrics$) will also result in multiple parts.If missing, only the
Metriccolumns will be used. If theMetriconly has a single column andpart_foreachis missing, then a single box (per-x-axis position) is created.Example¶# the columns under metrics also result in parts part_foreach: cols: [col5, col6] # create a box part for each unique combination of values in col5 and col6 # optional: exclude specific combinations (can also use cols from group_foreach, box_foreach, etc.) jp_except: "(col1 == 'A') && (col5 == 'B')"
- field box_width: float = 0.6¶
The width of each box.
- field box_padding: float = 0.0¶
The space between boxes within a group.
- field group_padding: float = 0.1¶
The space between groups.
Additional Components¶
- pydantic model doespy.etl.steps.colcross.components.DataFilter[source]¶
Filter the DataFrame to include only the specified values from a predefined list and establish a sorting order.
Example¶data_filter: allowed: col1: [val1, val2] # filter out rows where col1 is not val1 or val2 + sort col1 (in that order) col2: [val3, val4, val5] # filter out rows where col2 is not val3, val4, or val5 + sort col2 # col3 is not present, so all values are allowed
- field allowed: Dict[str, List[str]] [Required]¶
A dictionary that maps column names to a list of allowed values.
If a column is not present in the dictionary, then all values are allowed.
The order of the values in the list determines the order of the values and thus also the order in the plots.
- pydantic model doespy.etl.steps.colcross.components.ColsForEach[source]¶
- field cols: List[str] [Required]¶
Performs a group by with the cols as keys and yields the resulting dataframes.
- field jp_except: Optional[str] = None¶
Skip certain combinations based on the data id (and parent data_id)
- field label: KwargsLabelFormatter = None¶
Allows to define a label for each group based on the data_id
- pydantic model doespy.etl.steps.colcross.components.SubplotGrid[source]¶
Create a grid of subplots within a single figure, where each subplot corresponds to a unique combination of values from specified row and column columns.
- field rows: List[str] [Required]¶
The columns that are used to define the rows in the subplot grid.
Create a row for each unique combination of values from the specified row columns. (see
jp_exceptfor defining exceptions, i.e., not all combinations)
- field cols: List[str] [Required]¶
The columns that are used to define the columns in the subplot grid.
Create a column in each row for each unique combination of values from the specified column columns. (see
jp_exceptfor defining exceptions, i.e., not all combinations)
- field jp_except: Optional[str] = None¶
Skip certain combinations of (row, col) based on the data id.
Options available in plt.subplots(..) to share the x-axis across subplots
Options available in plt.subplots(..) to share the y-axis across subplots
- field subplot_size: WidthHeight = WidthHeight(w=2.5, h=2.5)¶
Size of each subplot (width, height) -> the size of the figure is determined by the number of rows and columns in the grid.
- field kwargs: Dict[str, Any] [Optional]¶
kwargs for the plt.subplots(..) function (https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.subplots.html)
- pydantic model doespy.etl.steps.colcross.components.Metric[source]¶
The metric specifies the columns in the dataframe where the data is stored, along with details such as units. Additionally, it enables conversion to other units as needed.
Each subplot will be built based on exactly one metric.
- field value_cols: Union[str, List[str]] [Required]¶
Identify the column(s) in the dataframe containing the data values.
The semantic of multiple columns varies based on the chart type being used. For instance, in a stacked bar chart, multiple columns may represent distinct “stacked” segments within a bar.
To understand the semantic of these columns, consult the documentation of the specific chart type.
- field error_cols: Union[str, List[str]] = None¶
Identify the column(s) in the dataframe containing the error values.
The semantic of the error values depends on the chart type being used (see
value_colsabove). For example, in a bar chart, the error values may represent the error bars for the corresponding data values.
- field value_multiplicator: float = 1.0¶
A multiplicator to scale the data values to e.g., convert to a desired unit. For instance, if the data is in milliseconds and you want to convert it to seconds, set this value to 0.001.
new_value = old_value * value_multiplicator / value_divider
- field error_multiplicator: float = 1.0¶
A multiplicator to scale the error values to e.g., convert to a desired unit.
new_error = old_error * error_multiplicator / error_divider
- field value_divider: float = 1.0¶
A divider to scale the data values to e.g., convert to a desired unit. For instance, if the data is in milliseconds and you want to convert it to seconds, set this value to 1000.
new_value = old_value * value_multiplicator / value_divider
- field error_divider: float = 1.0¶
A divider to scale the error values to e.g., convert to a desired unit.
new_error = old_error * error_multiplicator / error_divider
- field unit_label: str = None¶
An option to specify the unit for data values (after the optional scaling).
This unit can be utilized when formatting labels by using the special identifier:
$metric_unit$as a placeholder.
- pydantic model doespy.etl.steps.colcross.components.LabelFormatter[source]¶
A label formatter that allows to customize the label based on a data_id.
Example¶label: template: "{system}: {workload}" # for data_id = {"system": "A", "workload": "B"} -> label = "A: B"
- field template: str [Required]¶
A template string that can contain placeholders in the form “{placeholder}”. The placeholder corresponds to column names (which are presend in the data_id)
- pydantic model doespy.etl.steps.colcross.components.LegendConfig[source]¶
- field label: Union[str, LabelFormatter] = None¶
The basic label format assigned to each artist. Using a label in the ArtistConfig / SubplotConfig will overwrite this label.
- field kwargs: Dict[str, Any] [Optional]¶
kwargs for ax level legend (no ax level legend if None). e.g. {loc: “upper center”, ncol: 4, bbox_to_anchor: [0.51, 0.075], columnspacing: 3.5, fancybox: True}
- pydantic model doespy.etl.steps.colcross.components.AxisConfig[source]¶
- field scale: Literal['linear', 'log', 'symlog', 'logit'] = None¶
The scale of the axis
- field label: LabelFormatter = None¶
Axis Label
- pydantic model AxisLim[source]¶
- field min: Union[float, Dict[Literal['data_max_scaler', 'data_min_scaler'], float]] = 0.0¶
- field max: Union[float, Dict[Literal['data_max_scaler', 'data_min_scaler'], float]] = None¶
- field lim: AxisLim = None¶
Define the limits of the axis. Can either define a fixed value or scale the limits based on the data interval.
- field ticks: Union[Dict, int] = None¶
Set axis ticks (corresponds to matplotlib function set_xticks / set_yticks or it’s the number of ticks)
https://matplotlib.org/stable/api/_as_gen/matplotlib.axes.Axes.set_yticks.html
- field tick_params: Union[Dict, List[Dict]] = None¶
Additional options for the tick_params function.
https://matplotlib.org/stable/api/_as_gen/matplotlib.axes.Axes.tick_params.html
- field major_formatter: AxisFormatter = None¶
Label formatting function for major ticks on the axis.
The aviailable options are: - “round_short” -> which rounds the number to a short format (e.g., 1.2M)
- field minor_formatter: AxisFormatter = None¶
Label formatting function for major ticks on the axis.
The aviailable options are: - “round_short” -> which rounds the number to a short format (e.g., 1.2M)
Extending the ColumnCrossPlotLoader¶
The ColumnCrossPlotLoader module is designed with extensibility in mind, allowing for project-specifc customizations through hooks at various stages of the plot generation.
By leveraging these hooks, developers can integrate custom functions to modify plot configurations or introduce additional elements.
We showcase this functionality with an example, where the objective is to include a watermark label on each subplot.
See the resulting Bar Plot with Watermark.
Here how it’s achieved:
We extend the SubplotConfig with a watermark attribute (so that we can define the content of the watermark from the yaml config of the step).
We create a new loader, MyCustomColumnCrossPlotLoader, which replaces the default SublotConfig with the custom config containing the watermark.
We register a new function that adds the watermark to the subplot. We register it in the CcpHooks.SubplotPostChart hook, which is called after the chart has been created in the subplot.
import typing
from doespy.etl.steps.colcross.colcross import BaseColumnCrossPlotLoader, SubplotConfig
from doespy.etl.steps.colcross.hooks import CcpHooks
from typing import Dict, List, Union
import gossip
from matplotlib import pyplot as plt
import pandas as pd
class MyCustomSubplotConfig(SubplotConfig):
# INFO: We extend the default config and add a new attribute
watermark: str = None
class MyCustomColumnCrossPlotLoader(BaseColumnCrossPlotLoader):
# INFO: We provide a custom subplot config that extends the default config
# and override it here
cum_subplot_config: List[MyCustomSubplotConfig]
def setup_handlers(self):
""":meta private:"""
# NOTE: We can unregister function by name for a hook if needed
# for x in gossip.get_hook(CcpHooks.SubplotPostChart).get_registrations():
# if x.func.__name__ == "ax_title":
# x.unregister()
# NOTE: We can unregister all registered functions for a hook if needed
# gossip.get_hook(SubplotHooks.SubplotPostChart).unregister_all()
# install the class specific hooks
MyCustomColumnCrossPlotLoader.blueprint().install()
@MyCustomColumnCrossPlotLoader.blueprint().register(CcpHooks.SubplotPostChart)
def apply_watermark(
ax: plt.Axes,
df_subplot: pd.DataFrame,
subplot_id: Dict[str, typing.Any],
plot_config,
subplot_config,
loader,
):
if subplot_config.watermark is not None:
ax.text(0.5, 0.5, subplot_config.watermark, transform=ax.transAxes,
fontsize=20, color='gray', alpha=0.5,
ha='center', va='center', rotation=45)